













 JavaEE
JavaEE 鸿蒙应用开发
鸿蒙应用开发 HTML&JS+前端
HTML&JS+前端 Python+大数据开发
Python+大数据开发 人工智能开发
人工智能开发 跨境电商
跨境电商 电商视觉设计
电商视觉设计 软件测试
软件测试 新媒体+短视频
新媒体+短视频 集成电路应用开发
集成电路应用开发 C/C++
C/C++ 狂野架构师
狂野架构师 IP短视频
IP短视频


全部 Python+大数据新闻动态 Python+大数据技术文章 Python+大数据学习常见问题 技术问答
-
-

写爬虫是用多进程好?还是多线程好?
一般情况下,在选择是使用多进程还是多线程时,主要考虑的业务到底是IO密集型(多线程)还是计算密集型(多进程)。在爬虫中,请求的并发业务属于是网络的IO类型业务,因此网络并发适宜使用多线程;但特殊需求下,比如使用phantomjs 或者chrome-headless来抓取的爬虫,应当是多进程的,因为每一个phan/chro实例就是一个进程了,并发只能是多进程。 查看全文>>
Python+大数据技术文章2021-05-21 |传智教育 |写爬虫是用多进程好,多线程
-

Python爬取数据后使用哪个数据库存储数据比较好?
一般爬虫使用的数据库,是根据项目来定的。如需求方指定了使用什么数据库、如果没指定,那么决定权就在爬虫程序员手里,如果自选的话,mysql 和mongodb 用的都是比较多的。但不同的数据库品种有各自的优缺点,不同的场景任何一种数据库都可以用来存储,但是某种可能会更好。比如如果抓取的数据之间的耦合性很高,关系比较复杂的话,那么mysql可能会是更好的选择。如果抓取的数据是分版块的,并且它们之间没有相似性或关联性不强,那么可能mongodb 会更好。 查看全文>>
Python+大数据技术文章2021-05-21 |传智教育 |Python爬取数据用哪个数据库存储数据好
-

什么是事实表和维度表?【数据仓库】
每个数据仓库都包含一个或者多个事实数据表,事实表是对分析主题的度量,它包含了与各维度表相关联的外键,并通过连接(Join)方式与维度表关联。 查看全文>>
Python+大数据技术文章2021-05-21 |传智教育 |什么是事实表和维度表
-

Spark处理数据的速度比Hive更快?原因是什么?
Spark SQL比Hadoop Hive快,是有一定条件的,而且不是Spark SQL的引擎比Hive的引擎快,相反,Hive的HQL引擎还比Spark SQL的引擎更快。其实,关键还是在于Spark 本身快。那么Spark为什么快呢? 查看全文>>
Python+大数据技术文章2021-05-20 |传智教育 |Spark处理数据,Hive,大数据面试题
-

HTTPS有什么优点和缺点?
1、使用HTTPS协议可认证用户和服务器,确保数据发送到正确的客户机和服务器;2、HTTPS协议是由SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全,可防止数据在传输过程中不被窃取、改变,确保数据的完整性。3、HTTPS 是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本 查看全文>>
Python+大数据技术文章2021-05-19 |传智教育 |HTTPS优点和缺点
-

什么是死锁?【Python面试题】
若干子线程在系统资源竞争时,都在等待对方对某部分资源解除占用状态,结果是谁也不愿先解锁,互相干等着,程序无法执行下去,这就是死锁。 查看全文>>
Python+大数据技术文章2021-05-19 |传智教育 |什么是死锁
-
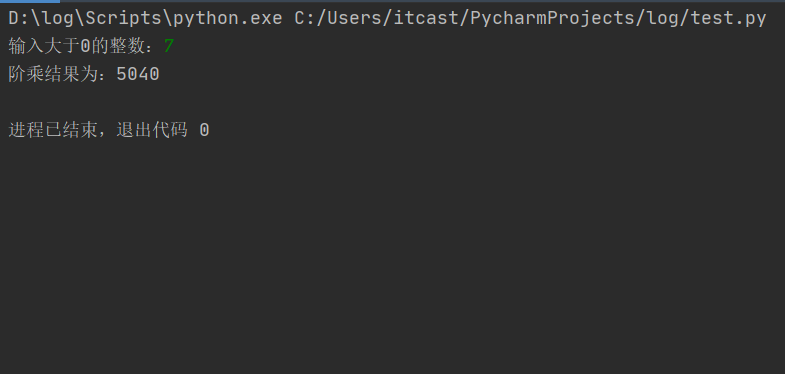
Python中for循环的用法|Pythonfor循环语句
for循环的作用:python for循环可以遍历任何序列的项目,如一个列表或者一个字符串。 查看全文>>
Python+大数据技术文章2021-05-19 |传智教育 |Python中for循环的用法
-
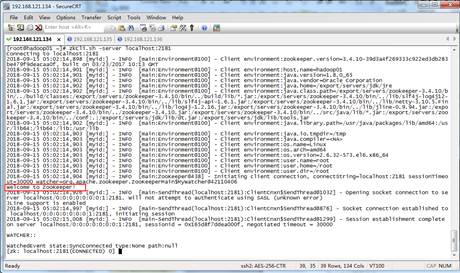
Shell教程:通过Shell命令操作Zookeeper
我们主要是通过Shell命令来操作Zookeeper。首先,启动Zookeeper服务;其次,连接Zookeeper服务。具体命令如下: 查看全文>>
Python+大数据技术文章2021-05-19 |传智教育 |通过Shell命令操作Zookeeper
-

















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All Rights Reserved 苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号