













 JavaEE
JavaEE 鸿蒙应用开发
鸿蒙应用开发 HTML&JS+前端
HTML&JS+前端 Python+大数据开发
Python+大数据开发 人工智能开发
人工智能开发 跨境电商
跨境电商 电商视觉设计
电商视觉设计 软件测试
软件测试 新媒体+短视频
新媒体+短视频 集成电路应用开发
集成电路应用开发 C/C++
C/C++ 狂野架构师
狂野架构师 IP短视频
IP短视频


全部 Python+大数据新闻动态 Python+大数据技术文章 Python+大数据学习常见问题 技术问答
-
-
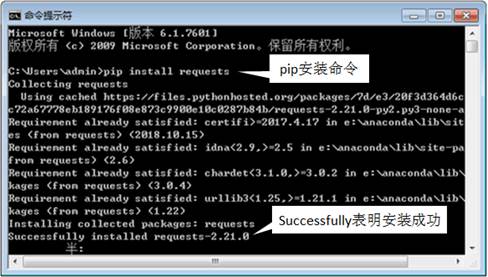
pip命令下载安装第三方模块【Python技术文章】
程序开发中不仅需要使用大量的标准模块,而且还会根据业务需求使用第三方模块。在使用第三方模块之前,需要使用包管理工具——pip下载和安装第三方模块。 查看全文>>
Python+大数据技术文章2021-06-16 |传智教育 |第三方模块,pip命令
-

Python模块如何导入__all__属性?
Python模块的开头通常会定义一个__all__属性,该属性实际上是一个元组,该元组中包含的元素决定了在使用from…import 语句导入模块内容时通配符所包含的内容。 如果__all__中只包含模块的部分内容,那么from…import *语句只会将__all__中包含的部分内容导入程序。 查看全文>>
Python+大数据技术文章2021-06-16 |传智教育 |Python模块,all属性导入
-
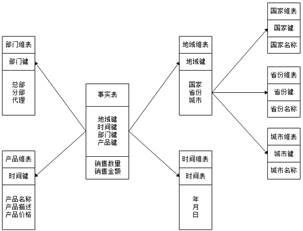
数据仓库的结构,数据仓库各部分详细介绍
在数据仓库建设中,一般会围绕着星型模型和雪花模型来设计数据模型。下面就来介绍一下这两种数据模型。 查看全文>>
Python+大数据技术文章2021-06-11 |传智教育 |数据模型,数据仓库
-

通用爬虫和聚焦爬虫介绍【Python技术文章】
根据使用场景,网络爬虫可分为通用爬虫和聚焦爬虫两种。通用爬虫是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。聚焦爬虫,是“面向特定主题需求”的一种网络爬虫程序。接下来,就对这两种爬虫分别进行介绍。 查看全文>>
Python+大数据技术文章2021-06-09 |传智教育 |通用爬虫和聚焦爬虫介绍
-

Scrapy框架的运行流程详解
Scrapy的运作流程由引擎控制,其过程如下:(1)引擎向Spiders请求第个要爬取的URL(s)。(2)引擎从Spiders中获取到第一个要爬取的URL,封装成Request并交给调度器。(3)引擎向调度器请求下一个要爬取的Request。 查看全文>>
Python+大数据技术文章2021-06-09 |传智教育 |Scrapy框架的运行
-

NumPy常用的数据类型有哪些?怎样进行转换?
NumPy支持比Python更多的数据类型。下面介绍一些常用的数据类型,以及这些数据类型之间的转换。通过“ndarray.dtype”可以创建一个表示数据类型的对象。要想获取数据类型的名称,则需要访问name属性进行获取,示例代码如下。 查看全文>>
Python+大数据技术文章2021-06-09 |传智教育 |NumPy中常用的数据类型
-

如何通过Anaconda管理Python包?
Anaconda集成了常用的扩展包,能够方便地对这些扩展包进行管理,比如安装和卸载包,这些操作都需要依赖conda。conda是一个在Windows、Mac OS和Linux上运行的开源软件包管理系统和环境管理系统,可以快速地安装、运行和更新软件包及其依赖项。 查看全文>>
Python+大数据技术文章2021-06-09 |传智教育 |Anaconda,Anaconda管理Python包
-

Python如何连连接MongoDB数据库?PyMongo常见语法
Python是目前比较流行的程序设计语言,特别是在人工智能和大数据分析处理上,市场空间是比较大的。写此同时,MongDB是比较流行的NoSQL数据库的解决方案,两者结合使用的场景非常多。 查看全文>>
Python+大数据技术文章2021-06-08 |传智教育 |Python如何连连接MongoDB数据库
-

















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All Rights Reserved 苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号