













 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


全部 Python+大数据新闻动态 Python+大数据技术文章 Python+大数据学习常见问题 技术问答
-
-

什么是线程?线程的分类
线程由线程ID、当前指令指针(PC)、寄存器集合和堆栈组成,它不能独立拥有系统资源,但它可与同属一个进程的其它线程共享该进程所拥有的全部资源。 查看全文>>
Python+大数据技术文章2021-07-20 |传智教育 |什么是线程,线程的分类
-

Shuffle是什么?有哪些工作流程
map阶段处理的数据如何传递给reduce阶段,是MapReduce框架中关键的一个流程,这个流程就叫shuffle。本章节内容来看一下shuffle的工作流程和工作机制。 查看全文>>
Python+大数据技术文章2021-07-20 |传智教育 |Shuffle的工作机制
-

Combiner的作用是什么?partition的作用是什么?
combiner其实属于优化方案,由于带宽限制,应该尽量map和reduce之间的数据传输数量。它在Map 端把同一个key的键值对合并在一起并计算,计算规则与reduce一致,所以combiner也可以看作特殊的Reducer。 查看全文>>
Python+大数据技术文章2021-07-20 |传智教育 |Combiner的作用,partition的作用
-
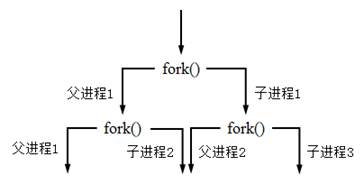
通过fork()函数创建进程方法介绍
在Unix/Linux操作系统中,通过Python的os模块中封装的fork()函数可以轻松地创建一个进程。fork()函数的声明如下: 查看全文>>
Python+大数据技术文章2021-07-20 |传智教育 |python创建进程
-

怎样创建单例和半生对象?
在Scala中,不能用类名直接访问类中的方法和字段,而是创建类的实例对象去访问类中的方法和字段。Scala中提供了object这个关键字用来实现单例模式,若单例对象名与类名相同,则把这个单例对象称作伴生对象,下面具通过体用代码演示单例对象和伴生对象的创建方法。 查看全文>>
Python+大数据技术文章2021-07-16 |传智教育 |创建单例和半生对象
-
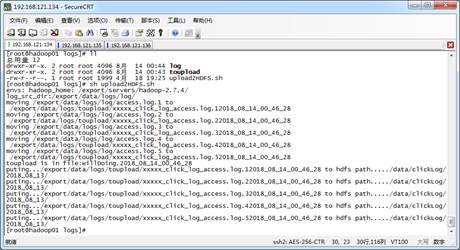
Shell怎样实现定时日志数据采集?【案例展示】
服务器每天会产生大量日志数据,并且日志文件可能存在于每个应用程序指定的data目录中,在不使用其它工具的情况下,将服务器中的日志文件规范的存放在HDFS中。通过编写简单的shell脚本,用于每天自动采集服务器上的日志文件,并将海量的日志上传至HDFS中。由于文件上传时会消耗大量的服务器资源,为了减轻服务器的压力,可以避开高峰期,通常会在凌晨进行上传文件的操作。下面按照步骤实现Shell定时日志采集功能 查看全文>>
Python+大数据技术文章2021-07-16 |传智教育 |定时日志数据采集,Shel定时日志上传
-

python异常处理:try-except语句与else子句的联合使用
异常处理的主要目的是防止因外部环境的变化导致程序产生无法控制的错误,而不是处理程序的设计错误。因此,将所有的代码都用try语句包含起来的做法是不推荐的,try语句应尽量只包含可能产生异常的代码。Python中try-except语句还可以与else子句联合使用,该子句放在except语句之后,表示当try子句没有出现错误时应执行的代码。其格式如下: 查看全文>>
Python+大数据技术文章2021-07-16 |传智教育 |else子句联合使用处理可能出现的程序异常
-

Python如何处理程序运行中的异常?
Python程序在运行时出现的异常会导致程序崩溃,这种异常处理方式并不友好,开发人员需要一种友好的方式处理程序运行时的异常。在Python中可使用try-except语句捕获异常,try-except还可以与else、finally组合使用实现更强大的异常处理功能。 查看全文>>
Python+大数据技术文章2021-07-16 |传智教育 |python处理程序异常
-

















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All Rights Reserved 苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号