













 JavaEE
JavaEE 鸿蒙应用开发
鸿蒙应用开发 HTML&JS+前端
HTML&JS+前端 Python+大数据开发
Python+大数据开发 人工智能开发
人工智能开发 跨境电商
跨境电商 电商视觉设计
电商视觉设计 软件测试
软件测试 新媒体+短视频
新媒体+短视频 集成电路应用开发
集成电路应用开发 C/C++
C/C++ 狂野架构师
狂野架构师 IP短视频
IP短视频


多种方法创建DataFrame【大数据技术文章】
更新时间:2021年03月23日14时14分 来源:传智教育 浏览次数:

在Spark2.0版本之前,Spark SQL中的SQLContext是创建DataFrame和执行SQL的入口,我们可以利用HiveContext接口,通过HiveQL语句操作Hive表数据,实现数据查询功能。而在Spark2.0之后,Spark使用全新的SparkSession接口替代SQLContext及HiveContext接口完成数据的加载、转换、处理等功能。
创建SparkSession对象可以通过“SparkSession.builder().getOrCreate()”方法获取,但当我们使用Spark-Shell编写程序时,Spark-Shell客户端会默认提供了一个名为“sc”的SparkContext对象和一个名为“spark”的SparkSession对象,因此我们可以直接使用这两个对象,不需要自行创建。启动Spark-Shell命令如下所示。
$ spark-shell --master local[2]
在启动Spark-Shell完成后,效果如图1所示。
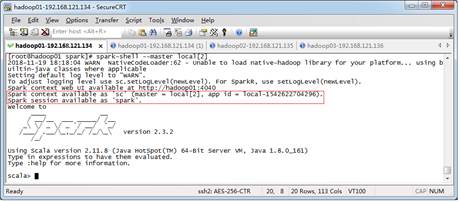
图1 启动Spark-Shell
在图1中可以看出,SparkContext、SparkSession对象已创建完成。创建DataFrame有多种方式,最基本的方式是从一个已经存在的RDD调用toDF()方法进行转换得到DataFrame,或者通过Spark读取数据源直接创建。
在创建DataFrame之前,为了支持RDD转换成DataFrame及后续的SQL操作,需要导入spark.implicits._包启用隐式转换。若使用SparkSession方式创建DataFrame,可以使用spark.read操作,从不同类型的文件中加载数据创建DataFrame,具体操作API如表1所示。
表1 spark.read操作
| 代码示例 | 描述 |
|---|---|
| spark.read.text("people.txt") | 读取txt格式的文本文件,创建DataFrame |
| spark.read.csv ("people.csv") | 读取csv格式的文本文件,创建DataFrame |
| spark.read.json("people.json") | 读取json格式的文本文件,创建DataFrame |
| spark.read.parquet("people.parquet") | 读取parquet格式的文本文件,创建DataFrame |
1.数据准备
在HDFS文件系统中的/spark目录中有一个person.txt文件,内容如文件1所示。
文件1 person.txt
zhangsan 20 lisi 29 wangwu 25 zhaoliu 30 tianqi 35 jerry 40
2.通过文件直接创建DataFrame
我们通过Spark读取数据源的方式进行创建DataFrame,在Spark-Shell输入下列代码:
scala > val personDF = spark.read.text("/spark/person.txt")
personDF: org.apache.spark.sql.DataFrame = [value: String]
scala > personDF.printSchema()
root
|-- value: String (Nullable = true)
从上述返回结果personDF的属性可以看出,创建DataFrame对象完成,之后调用DataFrame的printSchema()方法可以打印当前对象的Schema元数据信息。从返回结果可以看出,当前value字段是String数据类型,并且还可以为Null。
使用DataFrame的show()方法可以查看当前DataFrame的结果数据,具体代码和返回结果如下所示。
scala > personDF.show() +-------------+ | value | +-------------+ |1 zhangsan 20| |2 lisi 29| |3 wangwu 25| |4 zhaoliu 30| |5 tianqi 35| |6 jerry 40| +-------------+
从上述返回结果看出,当前personDF对象中的6条记录就对应了person.txt文本文件中的数据。
3.RDD转换DataFrame
调用RDD的toDF()方法,可以将RDD转换为DataFrame对象,具体代码如下所示。
scala > val lineRDD = sc.textFile("/spark/person.txt").map(_.split(" "))
lineRDD: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[6] at
map at <console>:24
scala > case class Person(id:Int,name:String,age:Int)
defined class Person
scala > val personRDD =
lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
personRDD: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[7] at map
at <console>:27
scala > val personDF = personRDD.toDF()
personDF: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more
field]
scala > personDF.show
+----+--------+----+
| id | name | age|
+----+--------+----+
| 1 |zhangsan | 20|
| 2 |lisi | 29|
| 3 |wangwu | 25|
| 4 |zhaoliu | 30|
| 5 |tianqi | 35|
| 6 |jerry | 40|
+----+--------+----+
scala > personDF.printSchema
root
|-- id: integer (nullable = false)
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
在上述代码中,第1行代码将文本文件转换成RDD,第4行代码定义Person样例类,相当于定义表的Schema元数据信息,第6行代码表示使RDD中的数组数据与样例类进行关联,最终会将RDD[Array[String]]更改为RDD[Person],第9行代码表示调用RDD的toDF()方法,就可以把RDD转换成了DataFrame了。第12-27行代码表示调用DataFrame方法并从返回结果可以看出,RDD对象成功转换DataFrame。
猜你喜欢:
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All Rights Reserved 苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号