













 JavaEE
JavaEE 鸿蒙应用开发
鸿蒙应用开发 HTML&JS+前端
HTML&JS+前端 Python+大数据开发
Python+大数据开发 人工智能开发
人工智能开发 跨境电商
跨境电商 电商视觉设计
电商视觉设计 软件测试
软件测试 新媒体+短视频
新媒体+短视频 集成电路应用开发
集成电路应用开发 C/C++
C/C++ 狂野架构师
狂野架构师 IP短视频
IP短视频


Spark Streaming框架有什么特点?【大数据培训】
更新时间:2020年05月29日15时20分 来源:Spark Streaming框架特点 浏览次数:
Spark Streaming是构建在Spark上的实时计算框架,且是对Spark Core API的一个扩展,它能够实现对流数据进行实时处理,并具有很好的可扩展性、高吞吐量和容错性。Spark Streaming具有如下显著特点。
(1)易用性。
Spark Streaming支持Java、Python、Scala等编程语言,可以像编写离线程序一样编写实时计算的程序求照的器。
(2)容错性。
Spark Streaming在没有额外代码和配置的情况下,可以恢复丢失的数据。对于实时计算来说,容错性至关重要。首先要明确一下Spak中RDD的容错机制,即每一个RDD都是个不可变的分布式可重算的数据集,它记录着确定性的操作继承关系(lineage),所以只要输入数据是可容错的,那么任意一个RDD的分区(Partition)出错或不可用,都可以使用原始输入数据经过转换操作重新计算得到。
(3)易整合性。
Spark Streaming可以在Spark上运行,并且还允许重复使用相同的代码进行批处理。也就是说,实时处理可以与离线处理相结合,实现交互式的查询操作。
Spark Streaming工作原理
Spark Streaming支持从多种数据源获取数据,包括 Kafka、Flume、Twitter、LeroMQ、Kinesis以及TCP Sockets数据源。当Spark Streaming从数据源获取数据之后,可以使用如map、 reduce、join和 window等高级函数进行复杂的计算处理,最后将处理的结果存储到分布式文件系统、数据库中,最终利用实时web仪表板进行展示。Spark Streaming支持的输入、输出源如下图所示。
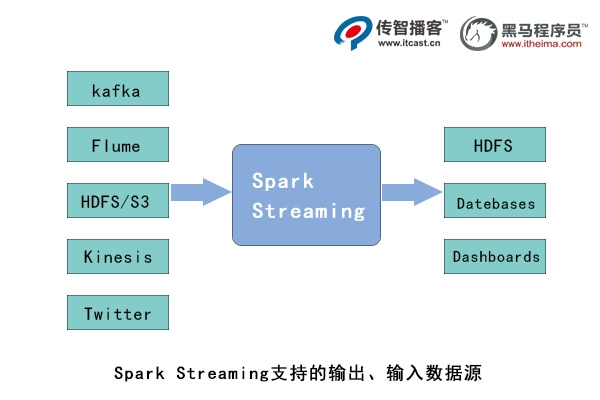
在上图中,Spark Streaming先接收实时输入的数据流,并且将数据按照一定的时间间隔分成一批批的数据,每一段数据都转变成Spark中的RDD,接着交由Spark引擎进行处理,最后将处理结果数据输出到外部储存系统。

猜你喜欢:
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All Rights Reserved 苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号